Build reasoning chains over paths using Knowledge Graph CompletionA large amount of work has been dedicated already on Knowledge base completion (KBC) which is an automated process that adds missing facts that can be predicted from existing ones already in the Knowledge base. However explaining the predictions given by a KBC algorithm is quite important for several real world use cases. This requires automatic extraction and ranking of multi-hop paths between a given source and a target entity from a knowledge graph. In this work we propose a simple approach that combines embedding-based models with a path building and ranking strategy to come up with the most probable explanations for a given prediction from a source to target. We assembled a knowledge graph by mining the available biomedical scientific literature and extracted a set of high frequency paths to use for validation. We demonstrate that our method is able to effectively rank a list of known paths between a pair of entities and also come up with plausible paths that are not present in the knowledge graph. For a given entity pair we are able to reconstruct the highest ranking path 60% of the time within the top 10 ranked paths and achieve 49% mean average precision. Our approach is compositional since any KBC model that can produce vector representations of entities can be used. |
 |
| Conference Publication: TextGraphs-13 at EMNLP 2019 | |
Application of Knowledge Graph Completion methods in Biomedical graphsThis work aimed at performing a critical analysis/evaluation of state-of-the-art knowledge base completion (KBC) methods applied to a biomedical graph. A biomedical graph consists of several entity types including Drugs, Diseases, Genes, Pathways etc and relations that link them and KBC methods for example can predict links, entities and relations. There are several KBC methods 1) embedding-based models, 2) relation-path reasoning models, 3) re-inforcement learning based path finding models and 4) rule-based reasoning models. In this work I trained ProjE, CompLEx (standard, Pytorch Big Graph, LibKGE), ConvE, RGCN, KBAT, DeepWalk, GraphSAGE and AnyBURL models and evaluated them in the biomedical graph under various settings and metrics to better understand their strengths and weaknesses. |
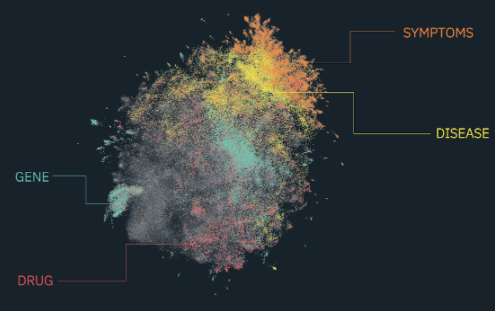 |
Fact Checking from Natural Text using Logical InferenceIn this work we created a method to support fact-checking of statements found in natural text such as online news, encyclopedias or even academic repositories, by detecting if they violate knowledge that is implicitly present in a reference corpus. The method combines the use of information extraction techniques with probabilistic reasoning, allowing for inferences to be performed starting from natural text. We are interested in the situation where assertions must be assessed by an algorithm, without requiring an authoritative source of truth. Therefore in this work we focus on assertions that we consider “implausible” because they implicitly conflict with a number of other statements present in a corpus of reference. The challenge here is how can we use techniques from information extraction and probabilistic reasoning to check facts that are implicit in a set of documents written in natural language? How can we decide if a claim is compatible with other claims, i.e. can it be true when the others are also true? Can we extract information that is not explicitly stated, but is implicitly present, in a set of documents? In this work we address this problem and this kind of approach will be useful for projects like Wikipedia, or to provide support to news fact checkers, but always in the form of assisting the job of humans. |
 |
| Conference Publication: IDA 2018 |
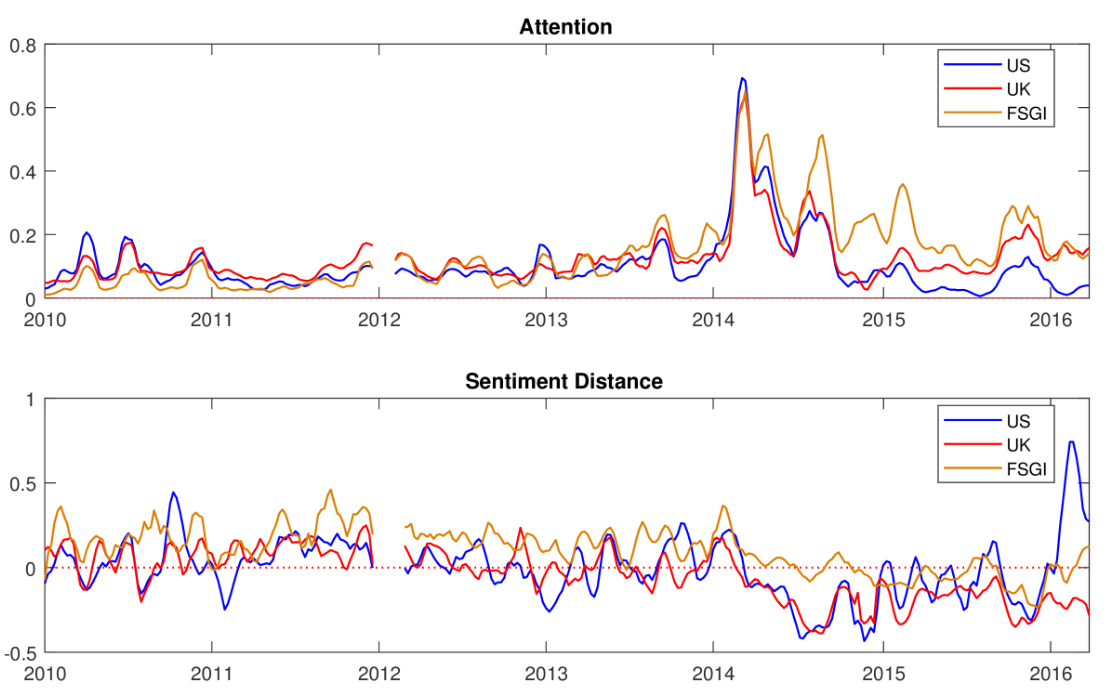
Detecting Opinion Shifts in Global News Content using Machine TranslationRapid changes in public opinion have been observed in recent years about a number of issues, and some have attributed them to the emergence of a global online media sphere. Being able to monitor the global media sphere, for any sign of change, is an important task in politics, marketing and media analysis. Particularly interesting are sudden changes in the amount of attention and sentiment about an issue, and their temporal and geographic variations. In order to automatically monitor media content, to discover possible changes, we need to be able to access sentiment across various languages, and specifically for given entities or issues. We present a comparative study of sentiment in news content across several languages, assembling a new multilingual corpus and demonstrating that it is possible to detect variations in sentiment through machine translation.
|
 |
| Conference Publication: IDA 2018 |
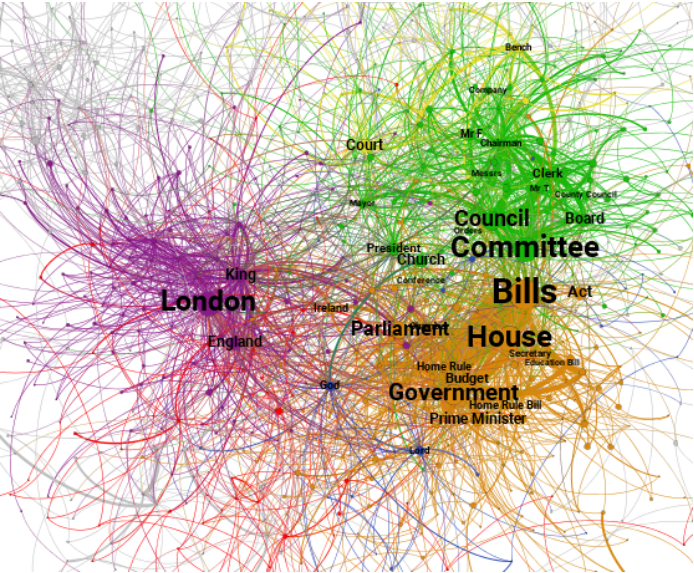
Narrative Network Analysis of British Power StructuresThis work looks specifically at the roles of key players in British society over a 150 year period from 1800-1950 and how these societal roles changed over this time. These players may be individuals such as the reigning King or Queen, or institutions such as the Church. The analysis was undertaken using narrative network analysis, turning digital information from 39.5 million local newspaper articles published in this time into a series of narrative networks. The complex social interactions were transformed into these visual networks by representing the different players of influence as network nodes, the actions of these influencers as links and the closely interacting sections of society built around them as their surrounding communities. The results of this data-driven analysis of 28.6 billion words taken from 150 years’ worth of newspaper reporting involves 29 networks comprised of 156,738 nodes connected by 230,879 edges. Another key element of the work was the detection of communities, which was performed by computing the frequency with which different key players performed interactions to or on each other. Once communities had been computed around the nodes, macro-communities were formed to show community structures which were persistent over the 150 year period across the majority of the 29 networks. |
 |
| Conference Publication: IDA 2017 |
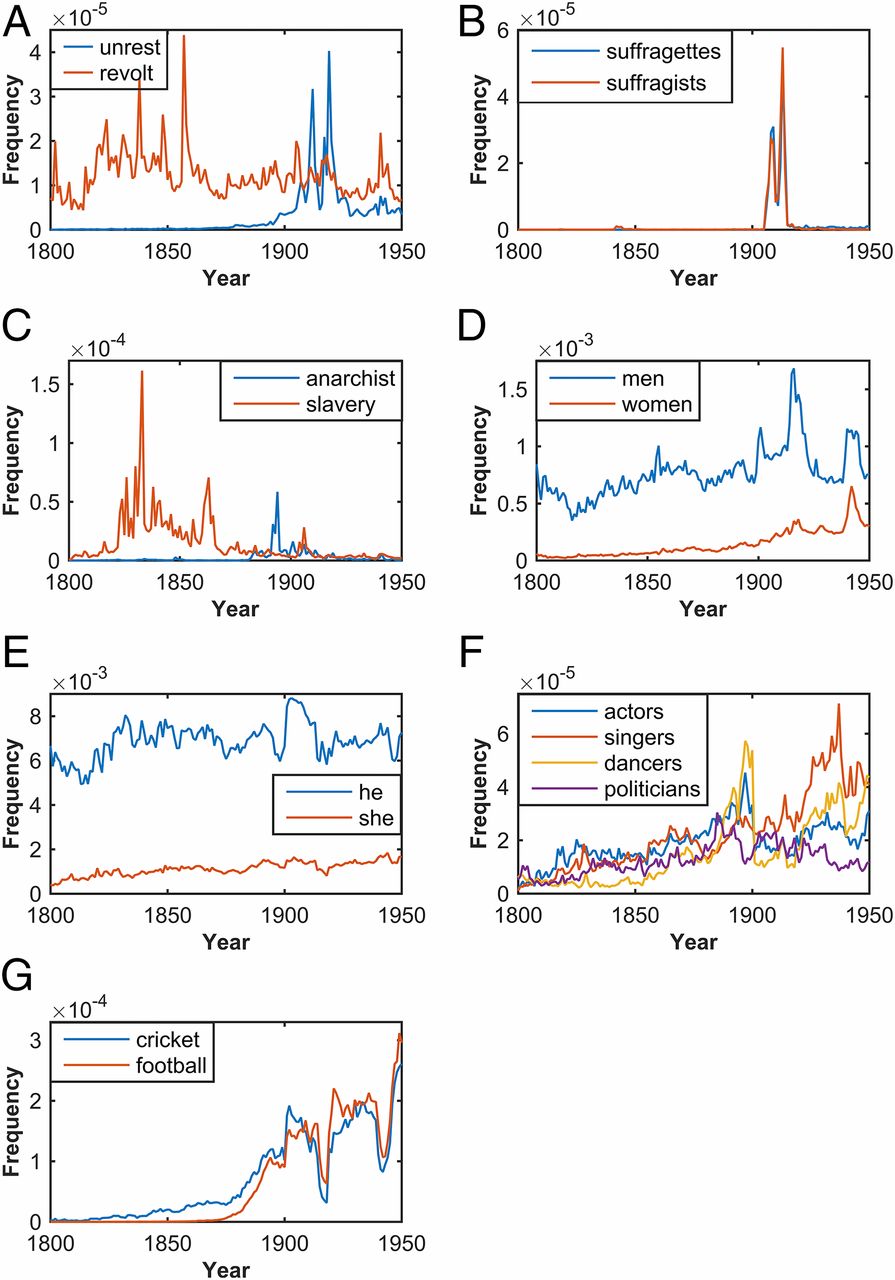
Content Analysis of 150 years of British PeriodicalsWhat could be learnt about the world if we could read the news from over 100 local newspapers for a period of 150 years? This is what we have done in this project, together with a social scientist and a historian, who had access to 150 years of British regional newspapers. The patterns that emerged from the automated analysis of 35 million articles ranged from the detection of major events, to the subtle variations in gender bias across the decades. The study has investigated transitions such as the uptake of new technologies and even new political ideas, in a new way that is more like genomic studies than traditional historical investigation. The main focus of the study was to establish if major historical and cultural changes could be detected from the subtle statistical footprints left in the collective content of local newspapers. How many women were mentioned? In which year did electricity start being mentioned more than steam? Crucially, this work goes well beyond counting words, and deploys AI methods to identify people and their gender, or locations and their position on the map. We have demonstrated that computational approaches can establish meaningful relationships between a given signal in large-scale textual corpora and verifiable historical moments. |
 |
| Journal Publication: PNAS Media Coverage: Times Magazine, Wired.co.uk, Phys.org, International Business Coverage (UK), Tech Times, iNews, Science Daily, WN.com, British Library Newsroom blog, Sciences et Avenir |
Gender Representation in Online NewsIt has long been argued that women are under-represented and marginalised in relation to men in the world’s news media. In this project we analysed over two million articles to find out how gender is represented in online news. The study, which is the largest undertaken to date, found men’s views and voices are represented more in online news than women’s. We analysed both words and images so as to give a broader picture of how gender is represented in online news. The corpus of news content examined consists of 2,353,652 articles collected over a period of six months from more than 950 different news outlets. From this initial data set, we extracted 2,171,239 references to named persons and 1,376,824 images resolving the gender of names and faces using automated computational methods. We found that males were represented more often than females in both images and text, but in proportions that changed across topics, news outlets and mode. Moreover, the proportion of females was consistently higher in images than in text, for virtually all topics and news outlets; women were more likely to be represented visually than they were mentioned as a news actor or source. Our large-scale, data-driven analysis offers important empirical evidence of macroscopic patterns in news content concerning the way men and women are represented. |
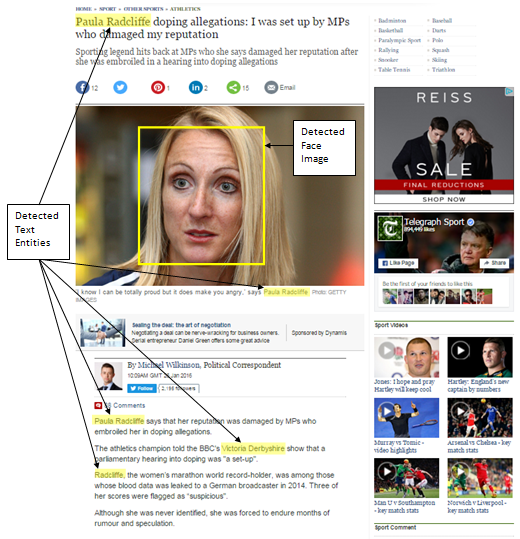 |
| Journal Publication: PLOS ONE Media Coverage: Science Daily, MyScience.org.uk, Independent, Medical Daily, Science Mag |
Scalable Preference Learning from Data StreamsIn this project we study the task of learning the preferences of online readers of news, based on their past choices. Previous work has shown that it is possible to model this situation as a competition between articles, where the most appealing articles of the day are those selected by the most users. The appeal of an article can be computed from its textual content, and the evaluation function can be learned from training data. In this paper, we show how this task can benefit from an efficient algorithm, based on hashing representations, which enables it to be deployed on high intensity data streams. To solve this problem, our prior results indicate that one needs to solve a preference learning task that consists of classifying ordered pairs of articles [9]. We call this classifier a ranker. For the ranking procedure we learn an appeal function that separates pairs of more-appealing (i.e. popular) and less-appealing (i.e. non-popular) articles. We demonstrate the effectiveness of this approach on four real world news streams, compare it with standard approaches, and describe a new online demonstration based on this technology. We have trained rankers on data streams within a global interval of six years between 2008 and 2014 using both TFIDF representations (words) and scalable hash representations (h12). |
 |
| Conference Publication: WWW 2015 |
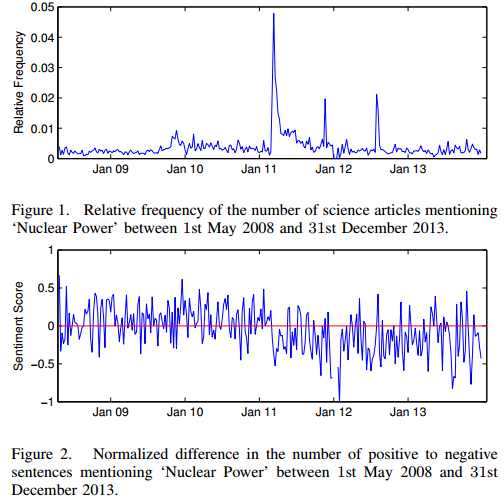
Coverage of Science in the Media: A study on the impact of the Fukushima disasterThe contents of English-language online-news over 5 years have been analyzed to explore the impact of the Fukushima disaster on the media coverage of nuclear power. This big data study, based on millions of news articles, involves the extraction of narrative networks, association networks, and sentiment time series. The key finding is that media attitude towards nuclear power has significantly changed in the wake of the Fukushima disaster, in terms of sentiment and in terms of framing, showing a long lasting effect that does not appear to recover before the end of the period covered by this study. In particular, we find that the media discourse has shifted from one of public debate about nuclear power as a viable option for energy supply needs to a re-emergence of the public views of nuclear power and the risks associated with it. |
 |
| Conference Publication: IEEE Big Data 2014 |
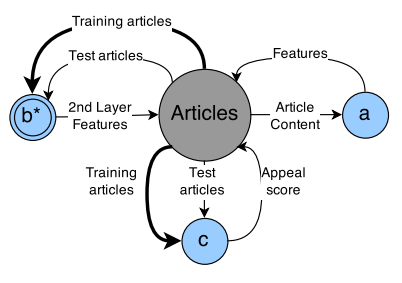
CompLACS: Composing Learning for Artificial Cognitive SystemsThe purpose of this project is to develop a unified toolkit for intelligent control in many different problem areas. I was involved in the creation of a web agent platform. The goal of the web-agent platform was to test algorithms and concepts, and to inspire new algorithms and concepts, within the domain of composing learning systems. The four scenarios identified within this goal were: Scenario 1: Annotation of News Articles, Scenario 2: Prioritising News Feeds and Scenario 3: Exploring the Web.Several modules were developed for online classifiers for learning news topics such as sports, politics, entertainment, education and technology and also to learn appeal of readers of different news outlets such as BBC, NPR etc. Another study was done combining modular adaptive modules into a single system, where an intermediate representation of the data was learnt (hidden layer) by supervised online learning based on web streams. This was then used as an input to train another system, realising a combined architecture. |
 |
| Project Website: CompLACS |
Detecting patterns in 2012 US Elections news coverageThe automated parsing of 130k news articles about the 2012 US presidential elections produces a network formed by the key political actors and issues, which were linked by relations of support and opposition. The nodes are formed by noun phrases and links by verbs, directly expressing the action of one node upon the other. This network is studied by applying insights from several theories and techniques, and by combining existing tools in an innovative way, including: graph partitioning, centrality, assortativity, hierarchy and structural balance.First, we observe that the fundamental split between the Republican and Democrat camps can be easily detected by network partitioning, which provides a strong validation check of the approach adopted, as well as a sound way to assign actors and topics to one of the two camps. Second, we identify the most central nodes of the political camps. This is the first study in which political positions are automatically extracted and derived from a very large corpus of online news, generating a network that goes well beyond traditional word-association networks by means of richer linguistic analysis of texts. |
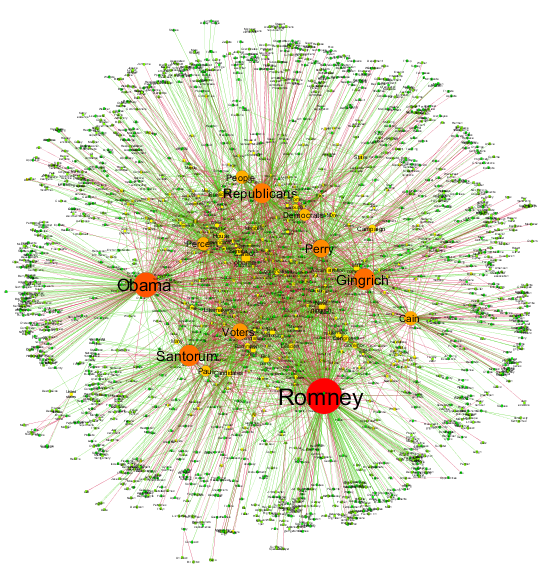 |
| Journal Publication: Big Data & Society Conference Publication: EACL 2012, IPP 2012 Media Coverage: Science Daily, Scientific Computing, ECN Mag, BusinessIntelligence.com, Phys.org, Significance |
Automated analysis of Gutenberg project stories for digital humanitiesThe wide availability of digitized literary works has given rise to a computational approach to analyzing these texts. The extraction of narrative networks from large corpora, discusses various issues relating to the validation of the resulting information, and shows an application of this methodology, to the analysis of three selected books containing stories from the Gutenberg Project. We demonstrate how this approach correctly identifies the key actors in each narrative and also some key features such as: “The Indian Tales” by Rudyard Kipling does not necessarily talk a lot about Indians, instead highlights British soldiers as the main heroes of the narration. The analysis of the “Heroic stories of American History” by Albert F. Blaisdell and Francis K. Ball identifies the most important generals who served the American army during the revolutionary war. This method can automate the labour intensive “coding” part of “Distant Reading” among other tasks, and therefore have relevance in the social sciences and the humanities. |
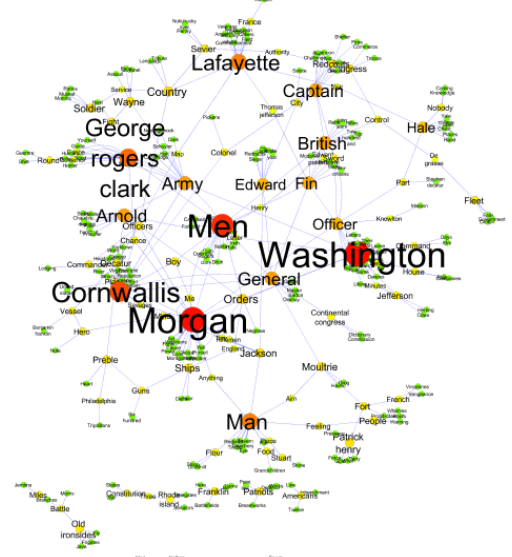 |
| Journal Publication: International Journal of Advanced Computer Science |
Automating Large scale analysis of narrative text: The methodologyWe present a methodology for the extraction of narrative information from a large corpus. The key idea is to transform the corpus into a network, formed by linking the key actors and objects of the narration, and then to analyse this network to extract information about their relations. By representing information into a single network it is possible to infer relations between these entities, including when they have never been mentioned together. Various measures have been introduced to increase the precision of the system thereby making sure information extracted is of high confidence.The contribution of this study is not in the improvement of tools for the processing of language (e.g. parsers) but in the development of a new methodology for the extraction of knowledge from a large corpus. The information we extract is not found in any individual document, but inferred from information distributed across the corpus, by effect of analysing a large network assembled by using all the documents. |
|
| Journal Publication: Natural Language Engineering Conference Publication: WAPA 2011 |
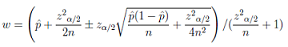
Multi-document summarisation using event based extractive summarisationWith the continuing growth of online information, it has become increasingly important to provide improved mechanisms to find and present textual information effectively. Event-based summarization is of great interest in recent research. Atomic events, which are the relationships between the important named entities can be automatically extracted from text and used for summarization.We developed a method to do automatic summaries using the key entites, actions and triplets found by our system pipeline incorporating a sentence scoring method based on textual features and using it to identify the summary sentences. This method proves to be useful by ranking 24 and 23 in ROUGE-2 and ROUGE-SU4 recall scores when compared across the scores of other 43 participants in the TAC 2010 guided summarization task. Future work is to be conducted in order to generate much more cleaner summaries using this information with other more sophisticated techniques. |
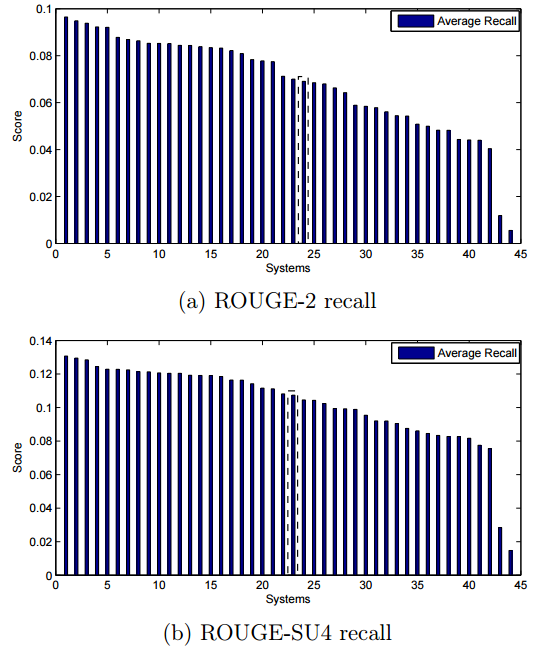 |
| PhD Thesis: Chapter |
Vidusuwa: A patient-centric telemedicine solutionThe pilot project of ViduSuwa, links the Specialist in a city with a patient in a peripheral setting via an electronic media; the solution is presently implemented in two hospitals in Sri Lanka. Patients in rural areas incur heavy expenditure in traveling long distances spending lot of time to consult Specialists in cities due to the lack of Specialists in their areas. This issue can be addressed by an eSolution that makes appropriate use of Electronic Medical Records (EMR) and Telemedicine technologies which enables the patient to consult a Specialist through eConsultation. The main benefit of implementing such an eSolution is that, it ensures the availability of the Specialist across a distance at many eClinics within the shortest possible time frame.Information and Communication Technology Agency of Sri Lanka (ICTA) together with University of Colombo School of Computing (UCSC) and Health Ministry of Sri Lanka launched the e-consultancy project, which is full of benefits to both patients and physicians. |
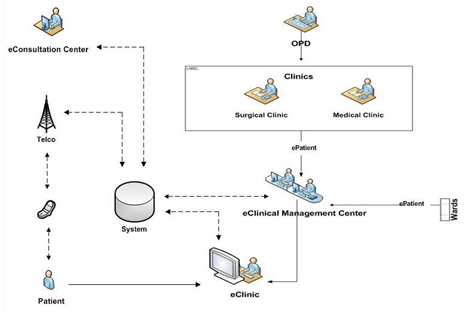 |
| Journal Publication: Sri Lanka Journal of Bio-Medical Informatics Conference Publication: ETELEMED’10 (e-health solution), ETELEMED’10 (m-health solution), eAsia 2009, IST-Africa (e-health business model), IST-Africa (e-health change-management model) |
