The rapid development of the World Wide Web and online information services has increased the accessibility of information everywhere. It is necessary to provide information that is more structured and synthesized in order to make things more efficient. Automatic generation of text through information extraction is a key area in linguistic research today. This includes automatic question and answering, document summarization and visualization techniques. Semantic graph is the major source for all these computations. It is the visual representation of a document’s semantic structure described using triplets (Subject – Verb- Object) extracted from sentences.
Semantic graphs are constructed through a series of sequential operations. The figure below describes it.
1) Text pre-processing
it is splitting of the input document into sentences.
2) Named Entity Extraction & Co-reference Resolution
Named entities refers to names of people, location and organisations. The tool GATE is used to perform this extraction. Terms which refer to the same entity also needs to be identified which is meant to be co-reference resolution. For example Anna Smith, A.Smith and Anna Maria Smith refer to the same entity. The figure below shows a document with two annotated named entities and their corresponding co reference.

3) Triplet Extraction
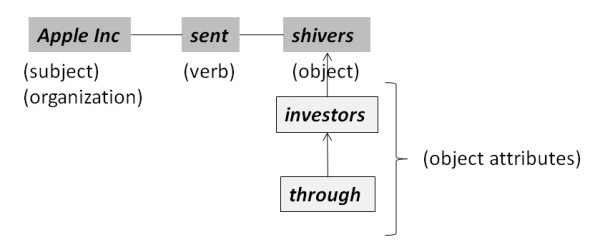
The core of a sentence is represented as a triplet with a Subject, Verb and Object elements assuming that it has enough information to express the meaning of the sentence. Triplets are much easier to process than complete sentences. They are obtained using the Penn Treebank parser which is based on pure syntactic analysis. the example of a triplet (Apple Inc – sent – shivers) is shown here.
4) Triplet Enhancement
In order to achieve deep syntactic analysis the co-referenced named entities and the extracted triplets are used to derive rules for anaphora resolution and semantic normalization. In the anaphora resolution the pronouns (he, she, it, they and I) are replaced with other document candidates. the subject elements are replaced with its co-referenced named entities. Then the triplets are assigned their corresponding WordNet synset. Wordnet is a lexical english database where nouns, verbs, adjectives and adverbs are grouped into sets of cognitive synonyms (synsets), each expressing a distinct concept. Triplet elements which share the same meaning can then be merged.
5) Triplet Merger
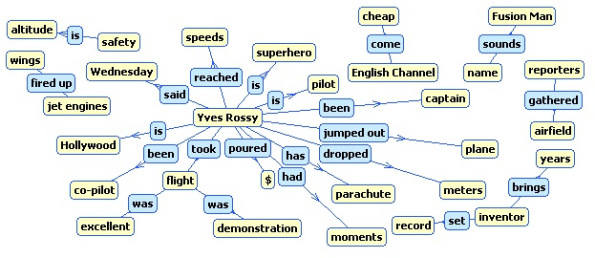
Finally triplets are linked based on a synonymy relationship forming a Semantic Graph, the direction being from the subject node to the object node and the connecting link is represented by the verb. A semantic graph obtained from a news article is shown below.
References
Dali, L., Rusu, D., Fortuna, B., Mladenic, D., & Grobelnik, M. (2009, April). Question answering based on semantic graphs. In Proceedings of the workshop on semantic search (sem-search 2009).
Rusu, D., Fortuna, B., Grobelnik, M., & Mladenic, D. (2009). Semantic Graphs Derived From Triplets with Application in Document Summarization. Informatica (Slovenia), 33(3), 357-362.
