Most of the work involves triplet extraction from documents using various tools and then performing co-reference resolution, anaphora resolution and semantic normalization. Finally the refined triplets are formed into a semantic graph. Later a SVM classifier is trained in order to get only the most relevant triplets for summarization purposes. To do this triplets are assigned a set of attributes like,
- linguistic attributes: the triplet type – subject, verb or object – the treebank tag and the depth of the linguistic node extracted from the treebank parse tree and the part of speech tag.
- graph attributes: consist of hub and authority weights, page rank, node degree, the size of the weakly connected component the triplet element belongs to, and others.
- document attributes: include the location of the sentence within the document, the triplet location within the sentence, the frequency of the triplet element, the number of named entities in the sentence, the similarity of the sentence with the centroid (the central words of the document), and so on.
The features are ranked according to the most important order. The order would be like object, subject, verb (all of these are words), location of the sentence in the document, similarity with the centroid, number of locations in the sentence, number of named entities in the sentence, authority weight for the object, hub weight for the subject, size of the weakly connected component for the object. Triplets are classified according to this rank by the classifier and later those triplets are used for document summarization. The figure below describes it.
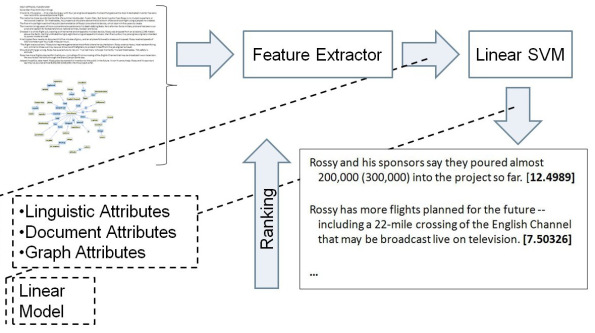
Another approach in summarization process has been tried by, obtaining summarized document versions by humans and then training the SVM classifier to learn it. This is done by a binary classification. Triplets were extracted from the document sentences which were used by humans in their summaries. Other triplets were considered as negative triplets. The SVM classifier was trained to differentiate between these two classes. Here also triplets were assigned attributes and then they were represented as vectors in order to train the SVM classifier. It is also observed that the performance of the classifier increases with the addition of attributes to the logical form features (in triplets).
Reference
Leskovec, J., Grobelnik, M., & Milic-Frayling, N. (2004). Learning sub-structures of document semantic graphs for document summarization, LinkKDD 2004.
